Blog: Hunt For The Unique, Stable, Sparse And Fast Feature Learning On Graphs (NIPS 2017).
• Tutorials
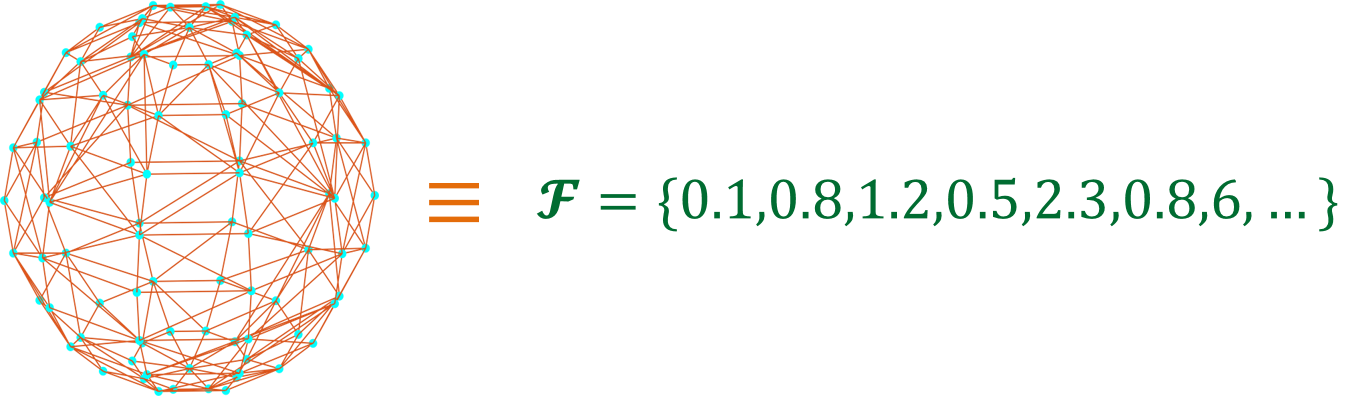
Graph is a fundamental but complicated structure to work with from machine learning point of view. Think about it, a machine learning model usually require inputs in some form of mathematical objects like vectors, matrices, real number sequences and then produces the desired outputs. So, the question is how we can convert a graph into a mathematical object that is suitable for performing machine learning tasks such as classification or regression on graphs.
For past one year, I have been working on developing machine learning models for graph(s) in order to solve two specific problems:
1) Graph Classification: Given a collection of graphs and associated graph labels where ( is the number of classes), we need to come up with a learning model or function that can classify or predict the label associated with a graph.
2) Node Classification: Given a graph , where is vertex set, is edge set & is adjacency matrix and labels where associated with each node, our task is to classify or predict the labels on each node. That is, come up a learning function .
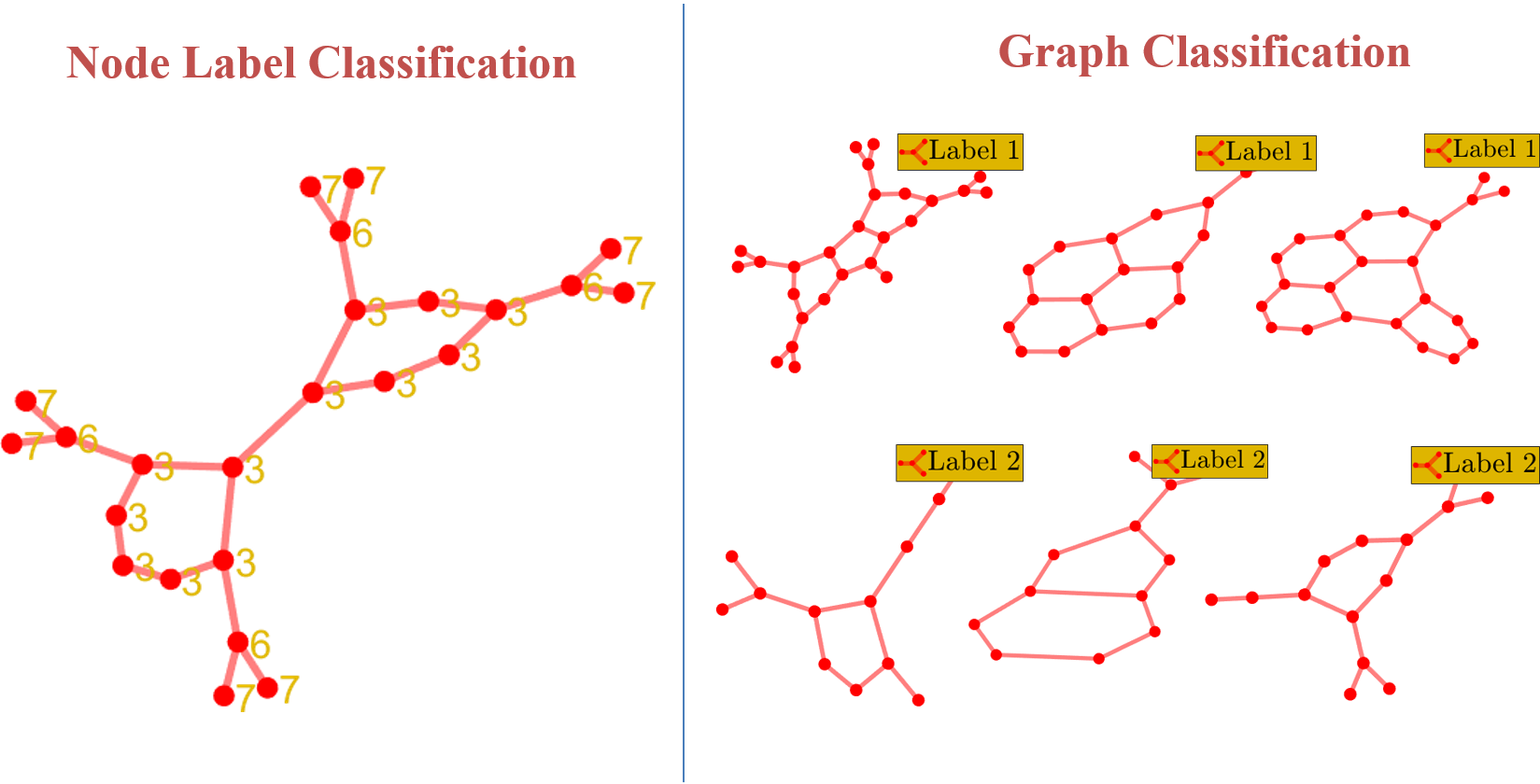
In this blog, I’ll mainly focus on graph classification problem but also show how we can leverage this work to perform node label classification as well. The fundamental problem in graph classification is comparing two graph structures. The main hurdle in comparing two graph structures is that we don’t know which node in the first graph corresponds to which node in other graph. This problem is universally known as graph isomorphism problem and so far we know it can only be solved in quasi-polynomial time and that too theoretically. Hence people came up with approximate but polynomial alternatives.
Previous studies on graph classification can be grouped into three main categories.
1) Graph Spectrum 2) Graph Kernels 3) Graph Convolutional Networks.
Graph Spectrum: Our majority work falls under first category and similar to graph kernels in certain aspects. But without going too much into what is graph kernel and graph convolutional network I’ll lay out the ideas behind graph spectrum.
First let’s discuss what spectrum mean? Spectrum is a collection of atomic elements (say in form of a set or vector or other mathematical object) to represent objects belonging to the same class (here class of objects could be an electrical signal, an audio signal or a chemical compound). For example, time series signal has a frequency spectrum. The importance of frequency spectrum is that one can recover the whole original signal from its frequency spectrum. Secondly from learning point of view, spectrum gives us a convenient and rich way to compare the similarity between two signals.
Now, the question is does graph has a spectrum? And if so, what are its atomic elements?
The most common graph spectrum you may heard of is graph Laplacian eigenvalue spectrum, where atomic elements are eigenvalues of graph Laplacian matrix. There are two more powerful graph spectrums based on group theory: Skew Spectrum and Graphlet Spectrum. The best thing about graph spectrum is that it atomic elements are solely depends upon the structure of the graph and thus invariant to permutation of graph vertex labels – a very important property desired from learning point of view.
We propose a new graph spectrum which is conceptually simple to understand but at the same time powerful enough as I’ll try to convince. Our Idea: Graph atomic structure (or spectrum) is encoded in the multiset of all nodes pairwise distances.
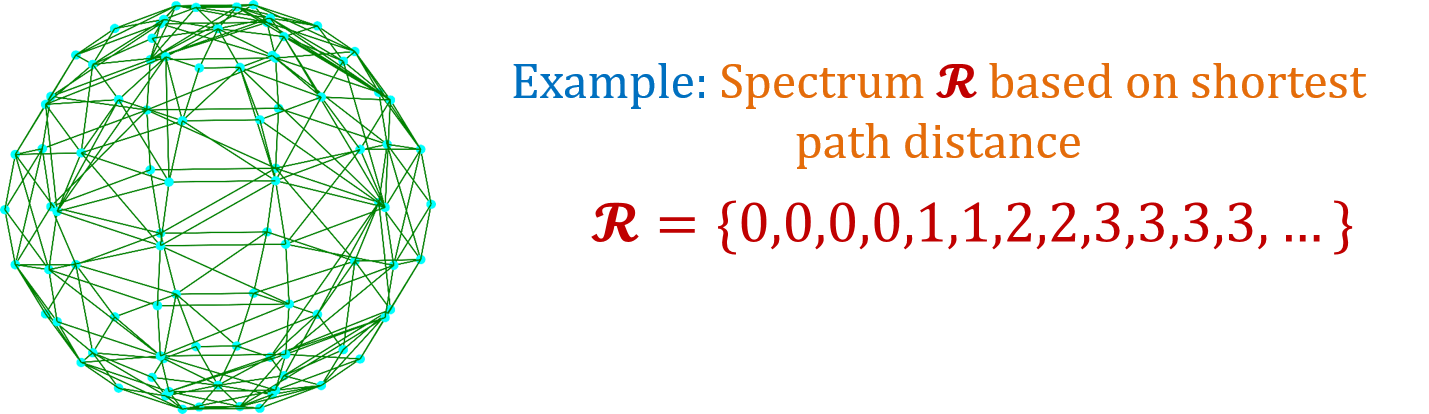
But what distance one should consider on a Graph?
is based on graph Laplacian spectral properties. Here & is Laplacian eigenvector and eigenvalue respectively.
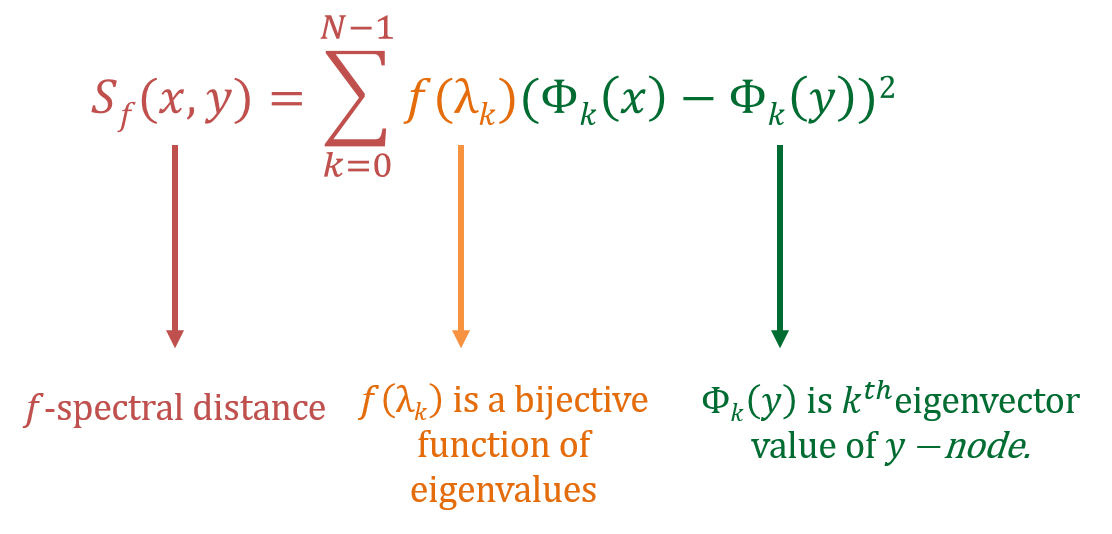
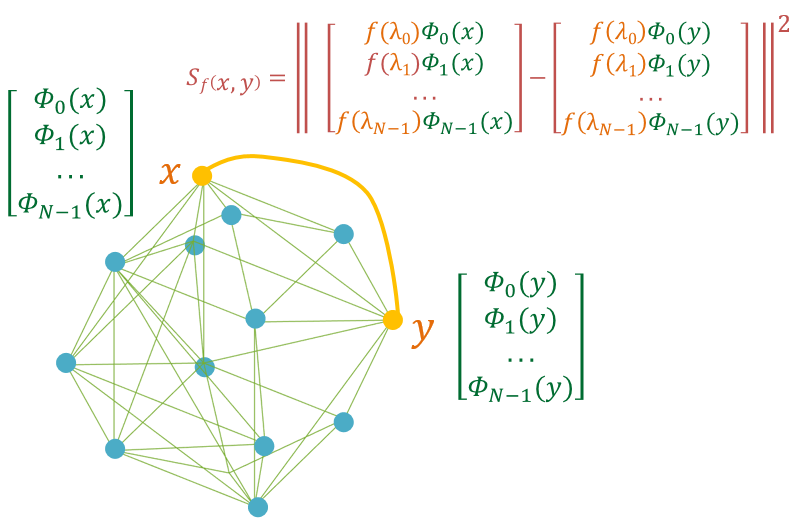
So what’s special about this family of distance? Depending upon , can capture different type of information about graph sub-structures.
Elements Encode Local Structure Information: For (), one can show that takes only -hop local neighborhood information.
Elements Encode Global Structure Information: For (), one can show that captures global structure information.
Some Known Graph Distances Can Be Derived From .
- Setting yields is harmonic or effective resistance distance.
- Setting yields biharmonic distance.
- Setting yields heat diffusion distance.
Theorem 1 (Uniqueness of ): The -spectral distance matrix uniquely determines the underlying graph (up to graph isomorphism), and each graph has a unique (up to permutation). More precisely, two undirected, weighted (and connected) graphs and have the same based distance matrix up to permutation, i.e., for some permutation matrix , if and only if the two graphs are isomorphic.
Implications: One of the consequence of Theorem is that the based on multiset of is invariant under the permutation of graph vertex labels. Unfortunately, it is possible that the multiset of some members can be same for non-isomorphic graphs (otherwise, we would have a polynomial time algorithm for solving graph isomorphism problem!). However, there is lot of HOPE. It is known that all non-isomorphic graphs with less than nine vertices have unique multisets of harmonic distance. While, for nine & ten vertex (simple) graphs, we have exactly & pairs of non-isomorphic graphs (out of total & graphs) with the same harmonic spectra. These examples show that there are significantly very low numbers of non-unique harmonic spectrums. Moreover, we empirically found that the biharmonic distance has all unique multisets for at-least upto ten vertices ( million graphs) and we couldn’t find any non-isomorphic graphs with the same biharmonic multisets. Further, we have the following theorem regarding the uniqueness of .
Theorem 2 (Uniqueness of Graph Harmonic Spectrum): Let be a graph of size with an unweighted adjacency matrix . Then, if two graphs and have the same number of nodes but different number of edges, i.e, but , then with respect to the harmonic distance multiset, .
Theorem 3 (Eigenfunction Stability of ): Let be the change in distance with respect to change in weight of any single edge on the graph. Then, for any vertex pair is bounded with respect to the function of eigenvalue as follows,
Implications: Decreasing function of (such as ) are more stable.
Conjecture (Sparsity of Graph Spectrum): For any graph , let represents the number of unique elements present in the multiset of , computed on an unweighted graph based on some monotonic decreasing function. Then, the following holds,
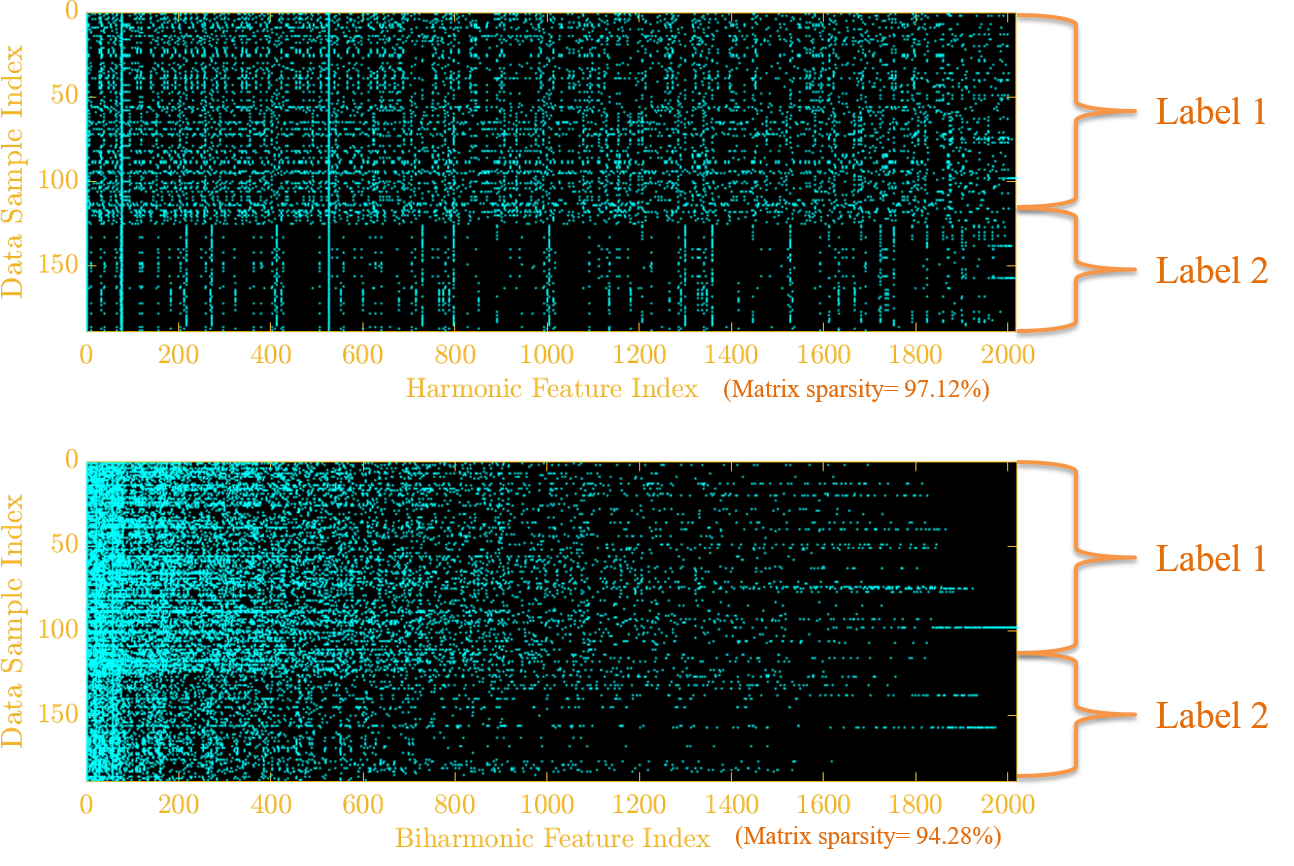
Implications: Harmonic Spectrum produce the most sparse features.
Feature Space of Harmonic and Biharmonic Spectrum
Lastly, one can show that the worst case complexity of computing is .
In the end, we take the histogram of spectrum to construct the graph feature vector. Overall our hunt leads to the harmonic distance as an ideal member of family for extracting graph features.
References:
- Saurabh Verma, Zhi-Li Zhang. Hunt For The Unique, Stable, Sparse And Fast Feature Learning On Graphs. In 31st Conference on Neural Information Processing Systems (NIPS 2017). [PDF]