Blog: Hunt For The Unique, Stable, Sparse And Fast Feature Learning On Graphs (NIPS 2017).
• Tutorials
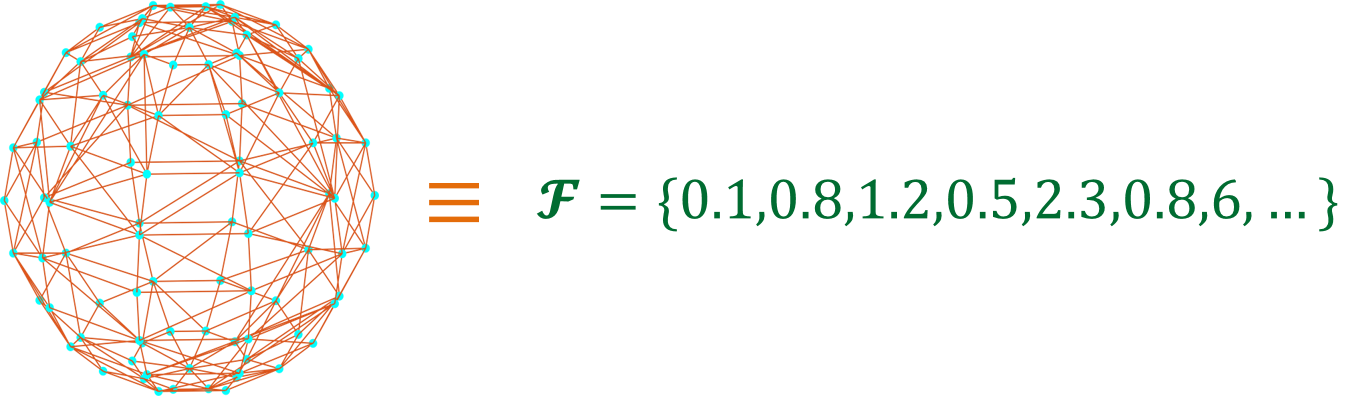
Graph is a fundamental but complicated structure to work with from machine learning point of view. Think about it, a machine learning model usually require inputs in some form of mathematical objects like vectors, matrices, real number sequences and then produces the desired outputs. So, the question is how we can convert a graph into a mathematical object that is suitable for performing machine learning tasks such as classification or regression on graphs.
For past one year, I have been working on developing machine learning models for graph(s) in order to solve two specific problems:
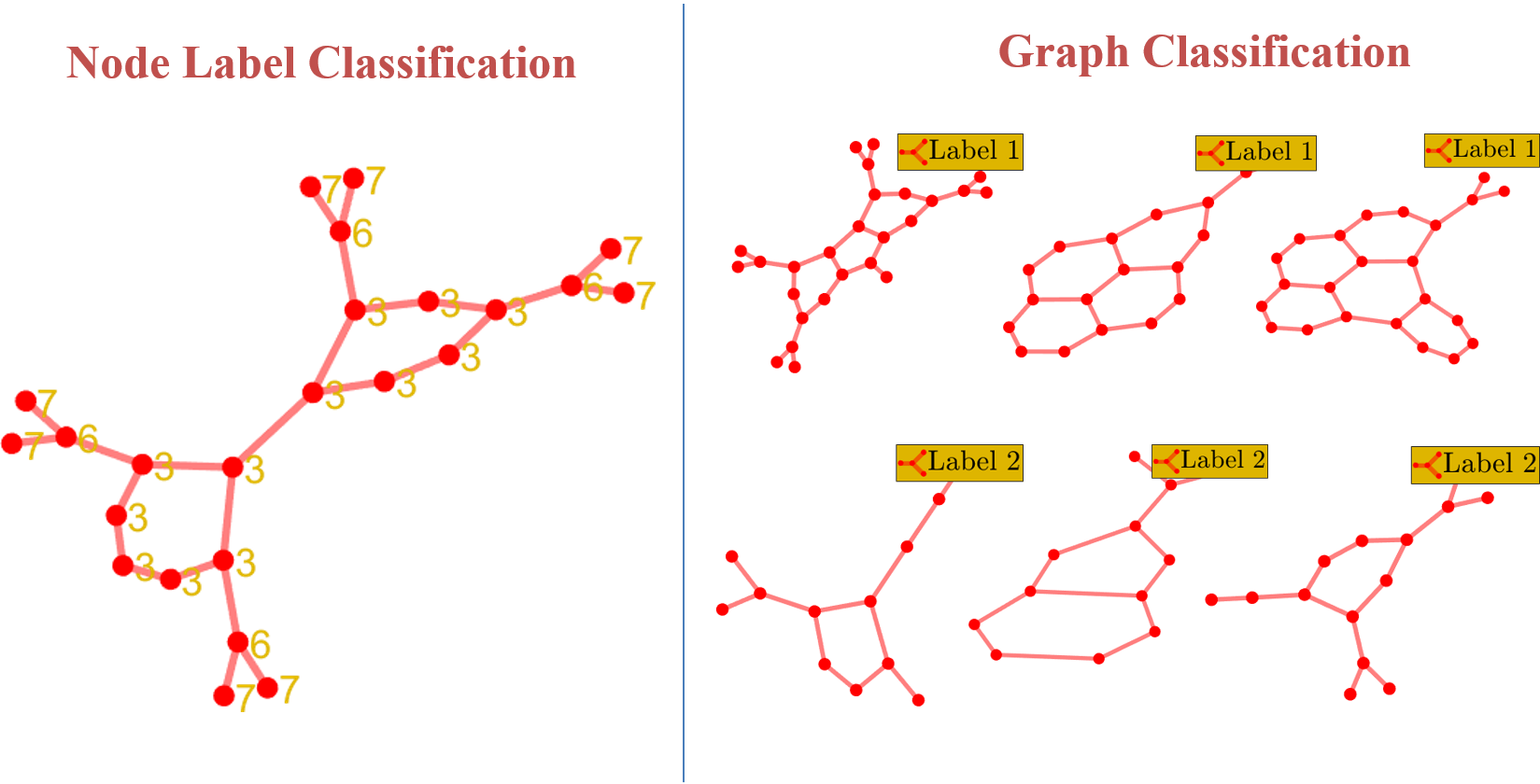
1) Graph Classification: Given a collection of graphs and associated graph labels where ( is the number of classes), we need to come up with a learning model or function that can classify or predict the label associated with a graph.
2) Node Classification: Given a graph , where is vertex set, is edge set & is adjacency matrix and labels where associated with each node, our task is to classify or predict the labels on each node. That is, come up a learning function .